

We made a deliberate bet when we built the Voyager® Software Development Kit's (SDK) pipeline builder: YAML-described pipelines, not code. A single YAML file would define everything from video input to model inference to postprocessing. The SDK would handle GStreamer orchestration, multi-stream management, image preprocessing like camera distortion correction, color conversion, and hardware dispatch. Application engineers could deploy detection and tracking pipelines without writing inference code at all.
That bet paid off. Production security systems, traffic analytics, and retail deployments run on YAML pipelines today. A detection-with-tracking pipeline looks like this:
pipeline:
- detections:
model_name: yolo26s
preprocess:
- letterbox:
width: 640
height: 640
- torch-totensor:
postprocess:
- decodeyolo10:
conf_threshold: 0.4
- tracker:
model_name: oc_sort
cv_process:
- tracker:
algorithm: oc-sort
bbox_task_name: detectionsAnd the application code to consume it:
stream = create_inference_stream(network="yolo26s-coco-tracker", sources=["camera.mp4"])
for frame_result in stream:
for obj in frame_result.tracker:
print(f"{obj.label.name} {obj.track_id}")The approach is compact, declarative, and fast. For standard detect-and-track workflows, this delivered on two of the three things edge AI developers need: performance and ease of use. The third, flexibility, is where the story gets interesting.
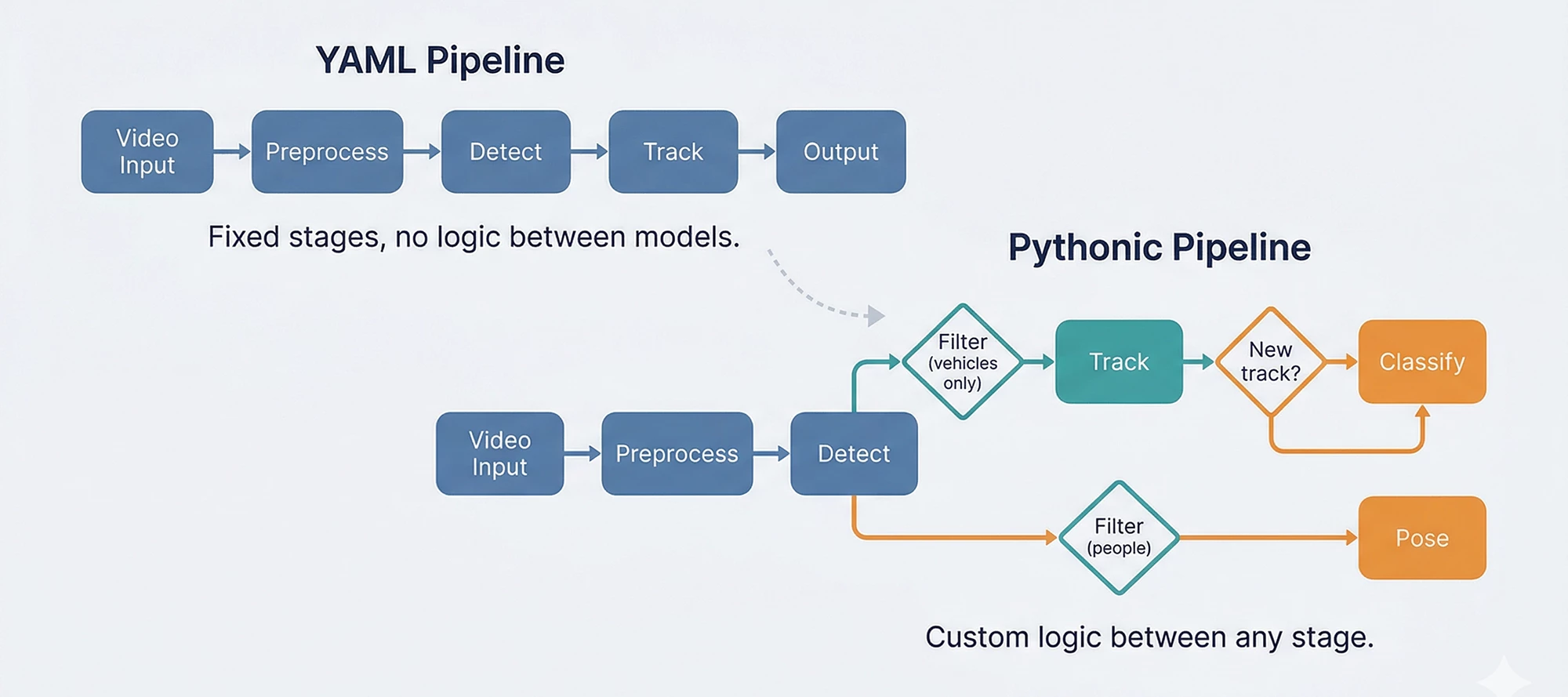
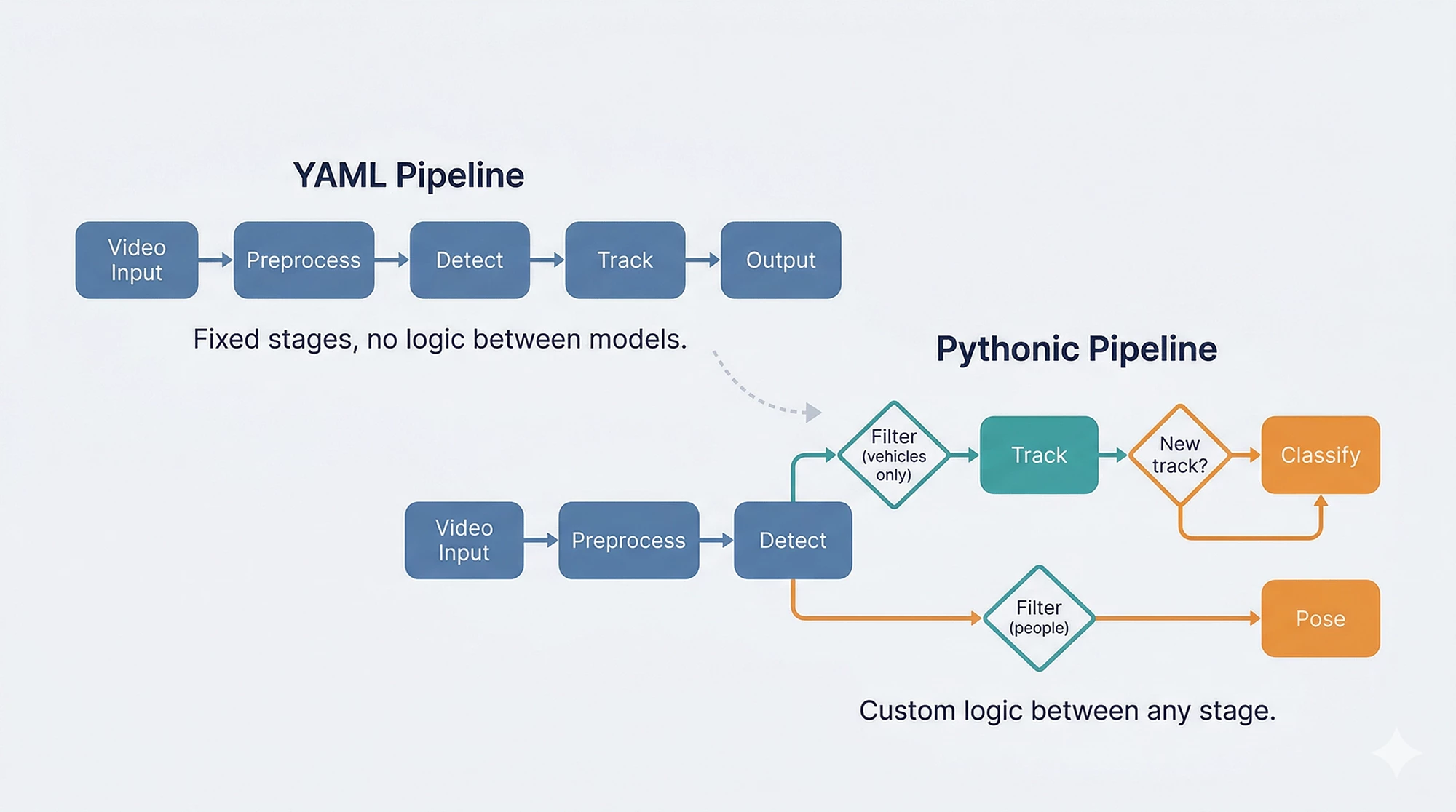
Then users started building things we didn't plan for
A customer needed to detect vehicles, track them, and run a secondary classifier only on newly appeared tracks entering a specific zone. Another wanted to split detections by class, run different models on each subset, and merge the results with custom business logic. A third wanted to prototype cascade pipelines in a Jupyter notebook before deploying to production.
The YAML pipeline can support all of these, and we have customers in production using such capabilities, but each new inter-stage pattern requires C++ and Python development to enable it. YAML cascades work through predefined reference patterns (source: roi, where: task_name) that connect stages together declaratively. Adding custom logic between stages, such as: "only classify if the track is new" or "skip this model if the confidence is below X and the object is in zone B," means building new C++ components and Python wrappers for each specific case. Voyager’s foundational runtime objects (InferenceStream and AxInferenceNet) are extensible to support inter-stage, but the development cost scales with every new pattern.
There was also a subtler friction: ML engineers prototype in PyTorch and NumPy. They think in tensors and function calls, not YAML keys. Asking them to translate a working Python prototype into YAML configuration added a step that slowed iteration without adding value.
The YAML abstraction was right for deployment. It wasn't fast enough for development iteration.
What if the pipeline IS the code?
That question led to the Pythonic Pipeline Builder — an experimental API where pipelines are composed in Python, not described in YAML. The same detection pipeline, in code:
from axelera.runtime import op
pipeline = op.seq(
op.letterbox(640, 640),
op.totensor(),
op.load('yolov8n-coco.axm'),
op.decode_detections(algo='yolov8', num_classes=80),
op.nms(),
op.to_image_space(),
op.axdetection(class_id_type=op.CocoClasses),
)
detections = pipeline(image)Each operator does one thing. op.seq chains them. The pipeline is a callable. This isn't a wrapper around the YAML system; it's a separate runtime that gives direct access to the same optimized C/C++ operators, with the flexibility to compose them however the use case requires.
But the real point isn't the detection pipeline. That works fine in YAML too. The point is what happens when you need to go beyond it.
The moment it pays off
Here's the vehicle-tracking scenario in Python. Detect vehicles, filter by class, track them, classify only newly appeared tracks. The kind of inter-stage logic that would normally require dedicated C++ development:
from axelera.runtime import op
detect = op.seq(
op.colorconvert('BGR', 'RGB'),
op.letterbox(640, 640),
op.totensor(),
op.load('yolov8n-coco.axm'),
op.decode_detections(algo='yolov8', num_classes=80),
op.nms(),
op.to_image_space(),
op.axdetection(class_id_type=op.CocoClasses),
op.filter(class_ids=[op.CocoClasses.car, op.CocoClasses.truck, op.CocoClasses.bus]),
)
tracker = op.tracker(algo='bytetrack', return_all_states=True)
classify = op.seq(
op.croproi(property='bbox'),
op.resize(size=256, half_pixel_centers=True),
op.centercrop((224, 224)),
op.totensor(),
op.normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
op.load('vehicle-type-classifier.axm'),
op.axclassification(),
op.topk(k=1),
)
for frame in video:
with op.frame_context(frame):
detections = detect(frame)
tracked = tracker(detections)
for obj in tracked:
if obj.state.name == 'new':
label = classify(frame, obj.tracked)
print(f"New vehicle {obj.track_id}: {label}")The filter, tracker, and classifier are separate pieces that compose freely. The "only classify new tracks" logic is a Python if statement, not a C++ component, callback library, or feature request. When the business rule changes (classify lost tracks too, or skip trucks, or add a second classifier for color), the change is a line of Python, not a development cycle.
You don't have to choose one
During this experimental period, the most practical path for many teams is a hybrid: keep YAML for what it already does well, and hand off to Python where flexibility matters.
Concretely: a YAML pipeline defines the top-level models (detection, pose, segmentation) without cascading. InferenceStream handles video acquisition, image preprocessing, multi-stream management, and primary inference at full GStreamer-optimized throughput. Then in your application code, Pythonic operators take the detection results and run tracking, filtering, secondary models, and business logic, all in Python.
This isn't a migration. It's a bridge. Teams keep their existing YAML pipelines and add Python where the development cost of enabling new patterns in YAML outweighs writing them directly. As the Pythonic builder matures, more of the pipeline can shift over incrementally.
What's ready and what's not
The experimental version of the Pythonic Pipeline Builder ships with Voyager SDK 1.6. We want to be clear about where it stands.
What works today: The operator API (op.seq, op.filter, op.tracker, op.foreach, custom operators), detection/classification/pose/segmentation pipelines, and four tracking algorithms. Models compile through the Ultralytics integration or the compiler API for any ONNX/PyTorch model. Getting started and pipeline overview docs ship with the SDK.
What's not ready yet: The optimized fused kernels that give YAML pipelines their peak throughput haven't been ported to the Pythonic builder yet. Each release will close this gap. The YAML and Pythonic paths also use different model compilation workflows today. The next beta will unify these so a model compiled once works with both. And a new video orchestration system is in development to replace the GStreamer dependency with something more flexible.
The goal has always been all three: performance, ease of use, and flexibility. The YAML builder delivered the first two. The Pythonic builder is how we add the third, without giving up what already works.
Which way do you lean?
This direction is shaped by how developers actually use the SDK. Do you prefer YAML for its simplicity? Is the Pythonic API closer to how you think about pipelines? Would a hybrid fit your workflow best?
Let us know in the comments. Your input directly shapes what we build next.

