

Axelera AI’s A-Tang Fan and Doug Watt explain how the Voyager SDK simplifies the complex task of deploying AI-powered video pipelines on edge devices. This blog explores how its model compiler, model builder, and pipeline builder offer flexible integration paths—whether you’re enhancing an existing VMS, building a new edge product, or optimising for performance.

Doug Watt | Director of AI Application Engineering

A-Tang Fan | Engineering Manager - Applications, Model Deployment Lead
Many real-world vision applications require the use of multiple deep-learning models, combined in sequence or parallel to perform different tasks. For example, outputting regions of people identified by an object detector into parallel models determining age and gender. Or cascading a vehicle detector into a license plate detector, followed by an optical character recognition model to read the plate. These multiple models are usually connected together with a camera to form an end-to-end inferencing pipeline that outputs images, detections and classifications. Application developers use this information to implement use cases such as crowd analysis and automatic issuing of speeding tickets.
Implementing video-streaming pipelines efficiently on performance-constrained edge systems is a hard problem to solve, requiring careful partitioning of the pipeline elements across the heterogeneous hardware components available. Edge AI systems often include a host CPU with embedded image-acceleration hardware, one or more AI accelerator cards connected via PCIe (such as Metis) and one or more input devices.
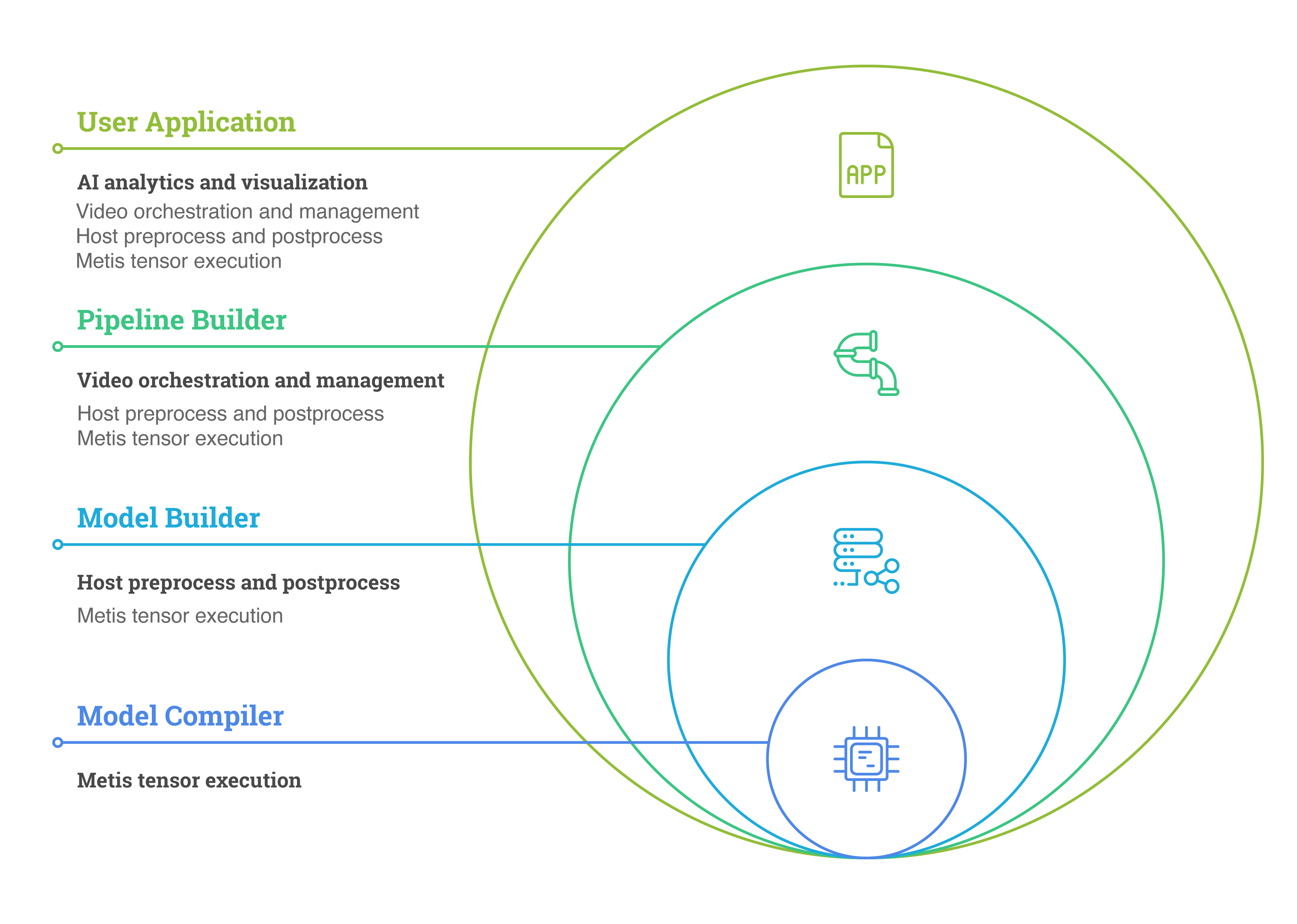
The Voyager SDK offers three powerful deployment tools for building Metis-based vision systems: the model compiler, model builder and pipeline builder. Each tool lets you work at a different level of abstraction.
- The lowest level provides full control over integrating Metis in systems with custom video handling
- The highest level lets you perform inferencing in applications while abstracting away all complexities of the underlying video pipeline implementation.
Together these tools balance control with ease of use, letting you select the development path that most closely matches your system integration requirements.
Model Compiler: The Traditional Approach
The Voyager model compiler supports the industry standard approach to AI deployment by compiling from a PyTorch or ONNX model. The compiler automatically quantizes your model for Metis hardware and generates binary code that performs tensor inferencing. You then integrate this code within your host application using the Voyager AxRuntime API.
AxRuntime is a Khronos-inspired API, supported in both C/C++ and Python, which provides precision control over:
- Execution of Metis code either synchronously or asynchronously within an end-to-end application pipeline
- The use of threading, queues and other low-level embedded programming techniques needed to run pipelines efficiently on hardware
The application must capture decoded images from a camera in the required color format, then handle pre-processing to prepare images for model input, and any post-processing needed to refine the raw output.
One approach is to utilize the PyTorch libraries in your application from training the model, like torchvision resize and crop transformations, along with a library such as OpenCV for decoding H.264 video and converting it to RGB. This usually results in good accuracy, but poor performance on embedded systems due to inefficient sharing of data between the hardware components.
An alternative approach is to implement the entire pipeline in a multimedia framework optimized for video streaming and buffer sharing. Axelera provides an integration plugin for the industry-standard GStreamer framework, based on AxRuntime, which integrates Metis inferencing into existing pipelines. GStreamer provides plugins for many image-processing operations, such as resizing and cropping, but requires custom plugin development for many AI-based operations. For example, post-processing a model output to identify overlapping boxes for the same object, cascading object detections into secondary models, and tracking detected objects over time. Moreover, utilizing off-the-shelf plugins for image pre-processing can significantly reduce accuracy of the deployed model unless the GStreamer implementation precisely matches the PyTorch libraries used during model training. See the dangers behind image resizing for a more detailed explanation.
Due to the effort required to achieve accurate, high-performance deployments using only the model compiler, it’s typically used to integrate Metis within existing solutions already discussed above, for example an AI-enabled video management system (VMS).
Model Builder: The Traditional Approach, Enhanced
The Voyager model builder extends the model compiler with support for pre-processing and post-processing on the host. It outputs a single model executable file optimized for execution on the host CPU with optional image acceleration hardware and one or more Metis devices.
Models can be input to the model builder as either ONNX files with both image and tensor operators, or as YAML files that reference a PyTorch model and list its pre-processing and post-processing operations declaratively. These operators are implemented in a Voyager computing kernel library, runnable on the host, with support for image accelerators such as Intel UHD Graphics (via VA-API) and ARM Mali (via OpenCL). The deployed model executable is then run with a single call to AxInferenceNet (part of the AxRuntime API), which internally pipelines the image and tensor operations across the available hardware as efficiently as possible.
AxInferenceNet is supported in C/C++, with Python support to follow. It builds upon AxRuntime with additional optimizations that:
- Allocate buffers to meet the alignment requirements of the hardware that executes the upstream and downstream elements
- Utilize mechanisms such as dma-buf to share buffers for DMA access, and interoperability extensions such as cl_khr_external_memory_dma_buf to map shared memory between hardware components without copying buffers
- Fuse together adjacent pipeline elements running on the same hardware component. For example, combining scaling, normalization and quantization into a single compute kernel to avoid generating intermediate data, minimizing compute and bandwidth requirements
In your application code, you can simply connect multiple AxInferenceNet elements together to construct more complex multi-model pipelines. The resulting pipeline can be integrated either directly with your application code (when using OpenCV, for example) or as part of a dedicated GStreamer pipeline using the Axelera integration plugin.
AxInferenceNet reduces the development effort needed to achieve accurate and performant model deployments while retaining control and flexibility over the construction and use of end-to-end pipelines within your application. It’s particularly useful for cases where the end-to-end video pipeline is already implemented, and where application-level fine-tuning is required. For example, when implementing an inferencing server or video management system that dynamically processes many streams and models.
Pipeline Builder: Application Development, Reimagined
The Voyager pipeline builder offers the highest level of abstraction:
- Describe your complete AI-based computer vision pipeline declaratively, at a high level, within a single YAML configuration file, and,
- Deploy and utilize the pipeline directly from within your application, without needing to consider low-level implementation details for your target hardware.
A YAML pipeline may include the following tasks:
- Conventional image pre-processing operations such as perspective transformations, denoising, low-light enhancement and color space conversion
- Model pre-processing operations such as resizing, scaling, cropping, letterboxing, normalization and tensor conversion
- Neural networks such as object detection, key-point detection and segmentation
- Post-processing operations such as tensor decoding, non-maximal suppression (NMS) and region of interest (ROI) extraction
- Cascading the output of one model as input to a secondary model. For example, outputting the ROI of a detected car into a secondary license plate detector
- Running multiple models in parallel. For example, to detect attributes such as a person’s gender, age and ethnicity
- Tracking detected objects over time. For example, based on the distance between ROIs in consecutive frames or using re-identification techniques
The pipeline builder deploys YAML files optimally across the hardware components available on the target system. Building upon AxRuntime and AxInferenceNet, it abstracts away all details of the low-level implementation such as connecting multiple models together, connecting the pipeline to one or more camera sources, and efficiently scheduling pipeline execution in parallel with the application code.
In your application code, simply declare an InferenceStream object (in either C/C++ or Python), connect the stream to one or more input devices (cameras, video files, etc.), and then iterate to obtain images and inference metadata. Voyager provides additional libraries for analyzing and visualizing inference metadata within your application.
InferenceStream objects support numerous advanced features and configuration options, which traditionally required the use of a fully-fledged video management system. These features are summarized in the table below.
| Feature | Benefit | Example usage |
| Just-in-time optimization of pipeline, based on I/O devices connected in the application | Deploy a pipeline once, and use anywhere Maximize runtime performance for any I/O configuration | Input video from different RTSP cameras, USB cameras and file-based workflows |
| Dynamic stream management | Run-time scalability: Add and remove video streams from a pipeline on-the-fly without needing to pause and restart the pipeline | Applications that dynamically change camera feeds |
| Dynamic model management | Run-time flexibility: Switch models used to analyze a stream on-the-fly without needing to pause and restart the pipeline | Applications that dynamically change models. For example, based on the scene |
| Per-stream configuration | Apply different tailored parameters to the pre-processing elements of each stream | Applications processing multiple camera streams with different calibration settings. E.g. perspective transformations and rotations |
| Fault-tolerant operation | Pipeline maintains functionality when individual channels experience outages, with automatic recovery when signals are restored | IP cameras operating in poor networking conditions |
| Adaptive frame processing | Maintains consistent performance through selective dropping and interpolation techniques Avoids queues from filling up leading to increased latency or lag | Record each incoming 4K stream at native 30fps while analyzing it at only 10fps Dynamically adjust the number of ROIs processed in a cascaded pipeline to keep up with the incoming frame rate while processing as much of a scene as possible (e.g. when analyzing a large crowd) |
Pipelines configured using InferenceStream objects can be rapidly re-configured to enable or disable the above features and fine-tuning parameters, all from within your application. In this way, Voyager allows you to focus on utilizing the results of AI inferencing to develop your business use cases while ignoring the complexities of optimizing video processing on the target hardware.
Selecting the Most Suitable Development Path
With Voyager SDK, you select the development path that most closely meets your development and integration requirements. The table below provides a few common scenarios.
| Example scenario | Recommended deployment tool and integration API | Reason for recommendation |
| Develop a new edge-based vision product, or upgrade an existing product to support AI inferencing use cases | Pipeline builder with InferenceStream | Invest your time in creating business value by differentiating your product with AI analytics (rather than spending time on embedded programming and performance optimization) |
| Integrate AI processing into existing vision products based on frameworks such as GStreamer or OpenCV | Model builder with AxInferenceNet | Re-use as much of your existing video-processing pipeline as possible Easily “plug-in” models to your pipeline with minimal code changes while achieving good performance |
| Add AI analytics to an existing VMS with its own video handling | Model compiler with AxRuntime | The VMS may contain existing software infrastructure for video decoding and image processing that needs to be used in the product |
Supporting The Community
Our goal with the Voyager SDK is to make AI development accessible to everyone, by providing robust and flexible tooling that meets the demands of real-world production deployments, and your feedback is essential in helping us achieve this goal.
Feel free to start a post on the Axelera AI community telling us how you’re using our tools, what works well and what you’d like to see improved — such as adding support for different image accelerators, image pre-processing tasks, models or media streaming frameworks — to help you develop and integrate AI inferencing within your applications.
We’re here to listen, improve, and unlock the full potential of AI at the edge together.