

Hi community!
It's been a while since my last update - lots happened! The short version: MotionFlow now runs fully on the Orange Pi with the Metis accelerator, and I've been iterating on making the whole thing actually usable in daily life.
Moving to Metis
I ripped out the OpenVINO inference path entirely and committed to the Axelera Voyager SDK as the only backend. I initially fell into the trap of pulling frames through OpenCV, which gave nice per-frame control, but a real performance bottleneck. Switching to the SDK's streaming API and letting its GStreamer pipeline handle everything made a huge difference! It manages video decoding and pipelined inference across the 4 Metis AIPU cores.
For this, I stitched together a simple custom pipeline combining yolov11l-pose and ByteTrack for tracking.
Multi-stream support was actually easier than expected - the SDK's create_inference_stream accepts multiple RTSP sources and tags each frame with a stream_id, so I can process several cameras in one pipeline. Currently running 3 cameras in my home setup.
Action Recognition: Rule-Based for Now
I built a rule-based action classifier that works directly on the pose keypoints. It uses geometric relationships (joint angles, body ratios, torso orientation) to classify actions like standing, sitting, lying down, walking, and a few more. It's not deep learning, but it's surprisingly robust for the "is someone on the couch?" use case.
I also experimented with an ML-based approach: a custom YOLOv11-Classify model that takes 30 frames of skeleton pose data stacked as channels. The idea is to run pose estimation on the NPU, build stacks out of a series of skeletons, then classify the temporal stack. The proof-of-concept worked, but results were really unstable.. this would need a lot more good training data and tuning, I guess.
The main advantage of ML would be recognizing dynamic actions - actual movements rather than static poses. But most of my current use cases (sitting, standing, lying down) are really just static postures, where the geometric approach is straightforward and robust. So for now, rule-based wins on pragmatism.
Web UI Overhaul
The config UI got a proper refactor - better styling, easier zone editing, and a camera switcher for multi-stream setups. It also gained the live view page, where you see exactly what the engine sees, overlaid with all the detection metadata.
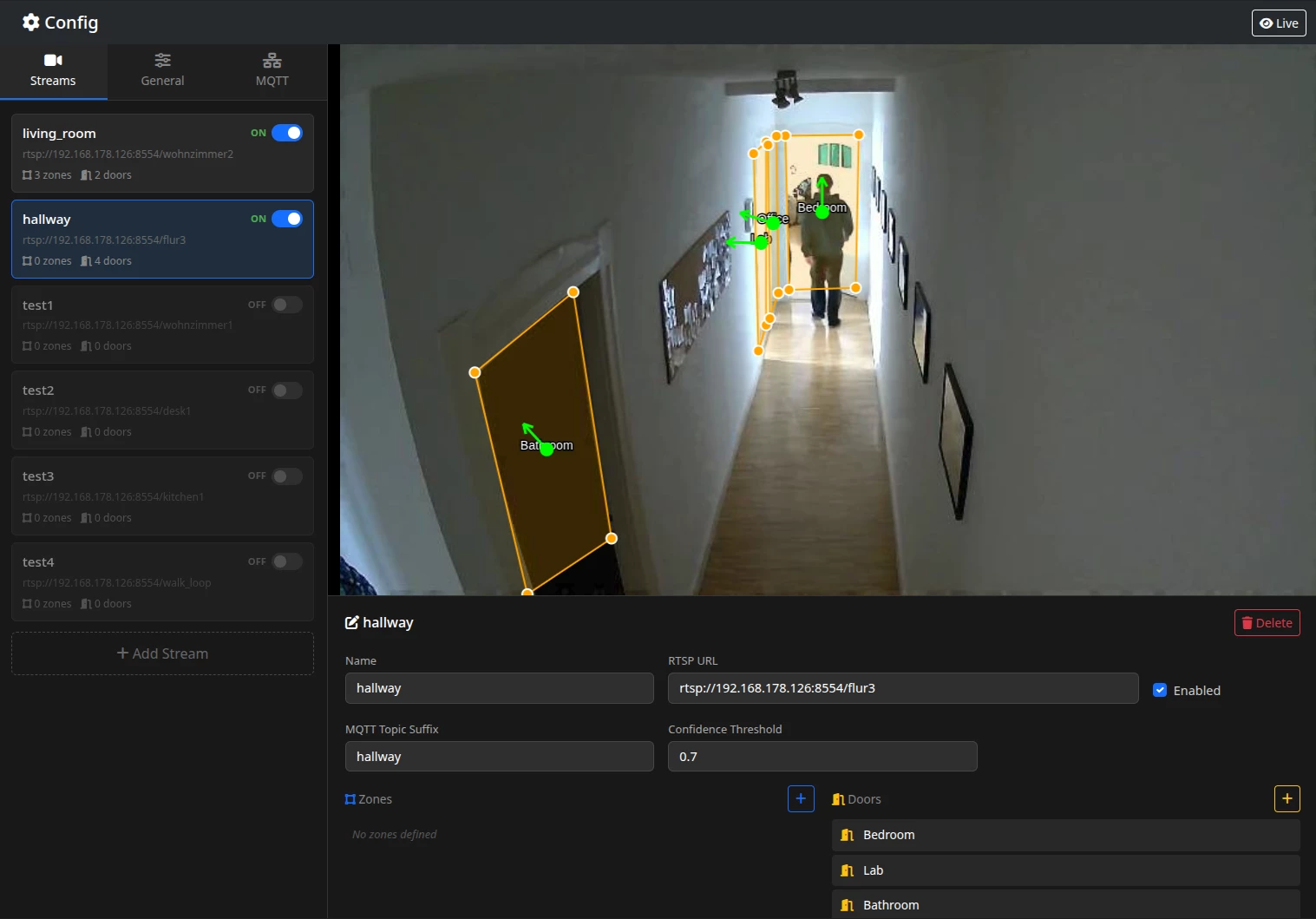
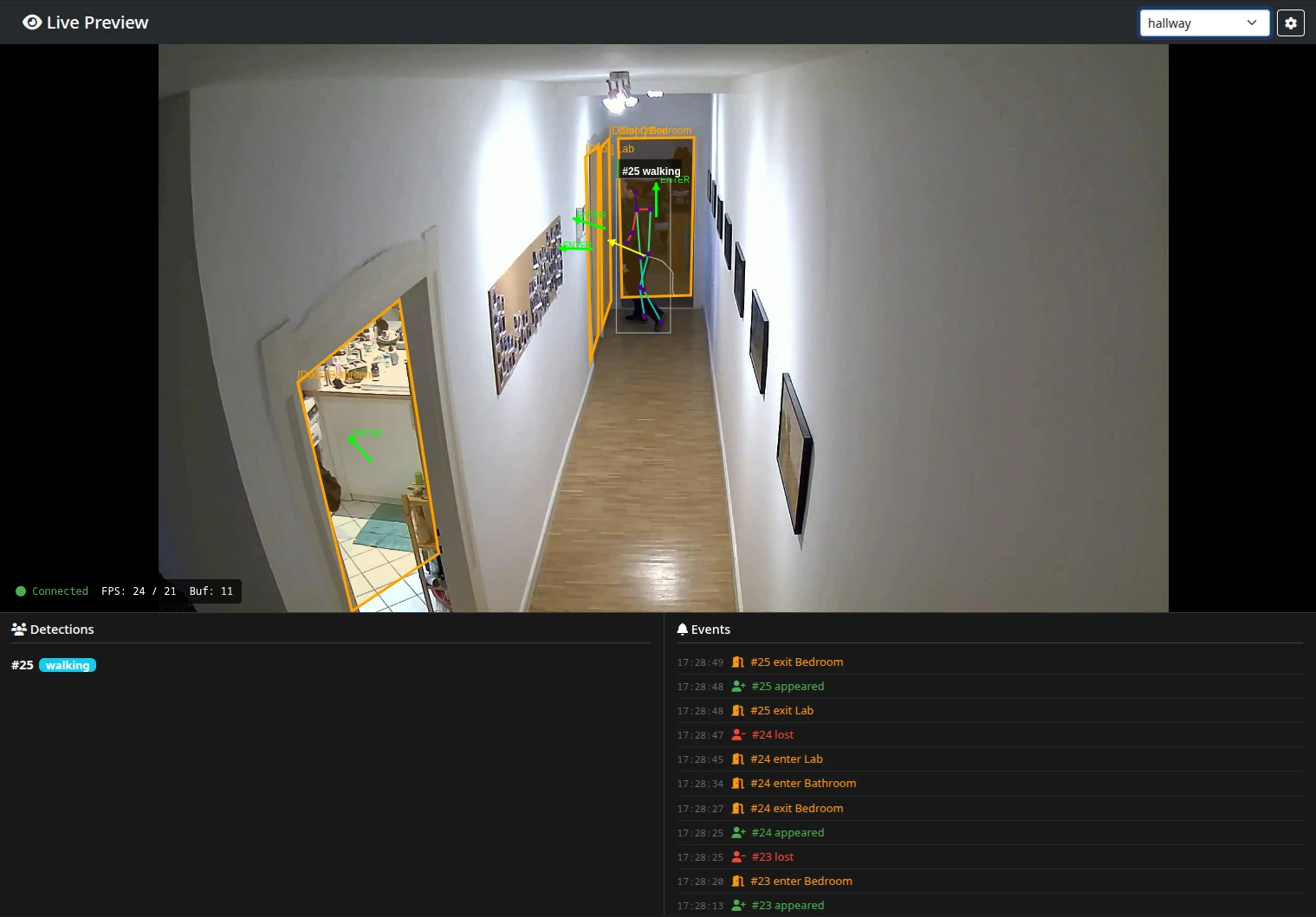
Remote View & IPC
Visualizing the inference results is only necessary for configuration and debugging. Therefore, I wanted to keep the computational overhead as little as possible:
- The app now broadcasts raw frames + metadata over IPC if requested
- The Web UI subscribes and shows a live debug view (skeletons, zones, events..)
- The visualization is drawn on the client's browser, so there is no additional load on the Orange Pi here
The broadcaster itself is zero-cost when nobody is watching - it only encodes frames and serializes metadata when there are active subscribers. So, in production with the web UI closed, there's no overhead.
Usability
Wrapped both apps in systemd services to move closer to an usable setup.
What's Next
- Smart Home integration: The MQTT events are flowing, but I need to build the actual Node-RED automations (lights, scenes) that react to them. That's the whole point, after all!
- Action recognition refinement: The rule-based system works for basic postures, but I want to improve on advanced postures like reading or on-the-phone. Maybe eventually switching to the ML pipeline for richer actions.
- Reliability: It's been running for a week now as a background service. Mostly stable, but the occasional hiccups need some attention.
Best,
- Jonathan