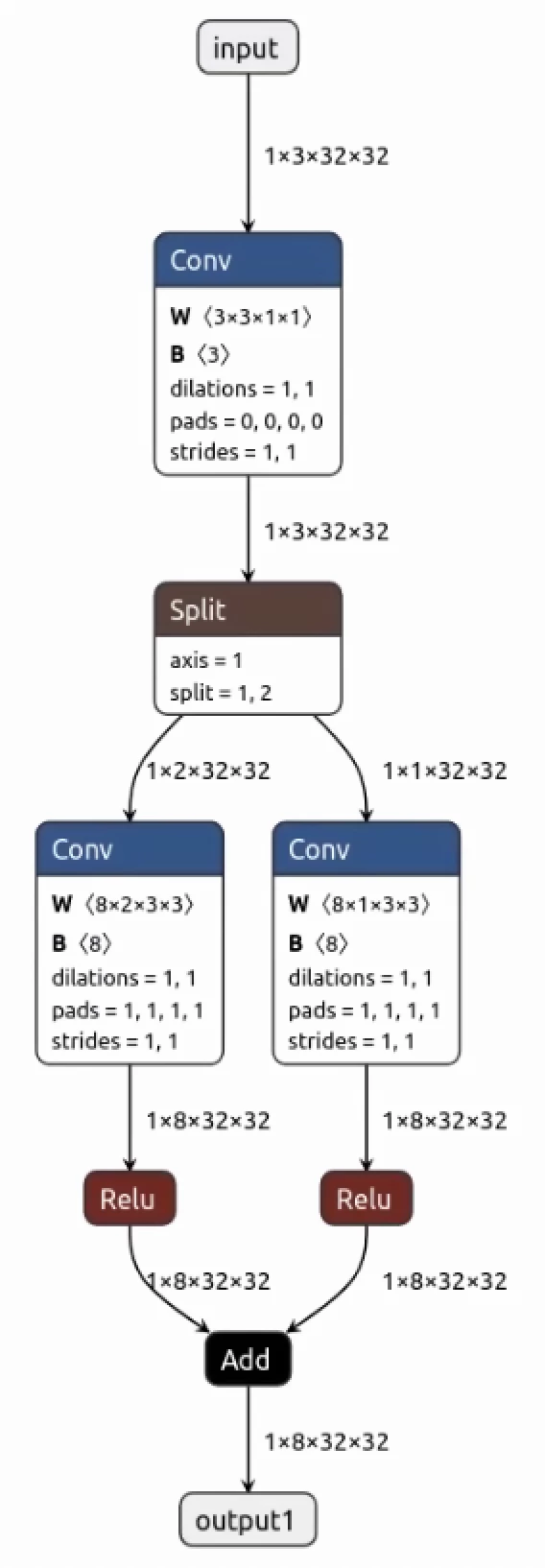
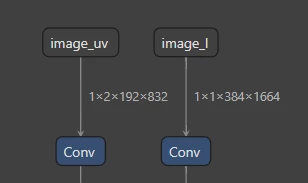
Hello, I’m new to voyager SDK and everything related to AXELERA and i need help deploying a custom onnx model that has 2 inputs and 20+ outputs, all i want for now is to manage to run an inference with my own dataset/image and to save to disk the raw outputs of the model. The input is a pair of 2 files. I have data in yuv format and it’s saved in input_y.npy and input_uv.npy. Do you have any idea how can i do this or if it’s possible from the voyager 1.3 or do i need to add a split layer so i need just 1 input and only then i can deploy it? Or to upgrade the voyager version to 1.4