(venv) root@iak:/home/voyager-sdk# ./inference.py yolov8s-coco-onnx ./media/traffic1_480p.mp4 INFO : Using device metis-1:1:0 WARNING : Failed to get OpenCL platforms : clGetPlatformIDs failed: PLATFORM_NOT_FOUND_KHR WARNING : Please check the documentation for installation instructions INFO : Default OpenGL backend gl,3,3 overridden, using gles,3,1 INFO : Network type: NetworkType.SINGLE_MODEL INFO : Input INFO : └─detections Stream Paused: 57%|██████████████████████████████████████████████████████▊ | 4/7 �00:00<00:00, 5.56/s]�ERROR]�axeWaitForCommandList]: Uio wait kernel failed with return code -1406. �ERROR]�axeCommandQueueExecuteCommandListsAsync]: Waiting for command lists failed: 0x70010001. terminate called after throwing an instance of 'std::runtime_error' what(): axr_run_model failed with Error at zeCommandQueueExecuteCommandLists(cmdqueue, n_cmdlists, cmdlists, nullptr): cmdqueue_run_cmdlists: 309: Exit with error code: 0x70010001 : ZE_RESULT_ERROR_NOT_AVAILABLE Aborted (core dumped) (venv) root@iak:/home/voyager-sdk#
Before I have tried to use the Accelerator on my laptop, also via docker and it ended with the same results. What does that error mean and how to troubleshoot it? May it be the accelerator firmware issue?
I’ve also tried the axdevice--refresh, however, it also didn’t help.
Page 1 / 1
Hi there @IAK, welcome on board!
Hmm, since you’ve seen this on both the Raspberry Pi and your laptop, it might be related to the runtime environment in Docker rather than the board firmware?
First quick thing to try: can you run this command inside your Docker container and share the output?
glxinfo | grep "OpenGL renderer"
This will help confirm whether OpenGL ES is available and functioning properly, which is required for inference display on the Pi5. If it’s working, missing or misconfigured, we can go from there
Hi @Spanner
Thanks, glad to be here! After running the glxinfo | grep "OpenGL renderer" command inside my docker I have the following output: ⬢ nDocker] ❯ glxinfo | grep "OpenGL renderer" OpenGL renderer string: V3D 7.1
Guess it is configured fine, isn’t it?
Ah, that’s good news! Well, not good news that you’re having an issue, but it’s good that we’ve confirmed that OpenGL is working Thanks for the info.
Maybe we should check that the Metis card is being recognised correctly? If you could run the following command inside the container and share the output:
axdevice
That should give us some info about its status, firmware, etc.
Ah, that’s good news! Well, not good news that you’re having an issue, but it’s good that we’ve confirmed that OpenGL is working Thanks for the info.
Maybe we should check that the Metis card is being recognised correctly? If you could run the following command inside the container and share the output:
axdevice
That should five us some info about its status, firmware, etc.
Facing the same issue. Device 0: metis-1:1:0 board_type=m2 fwver='v1.2.5' clock=800MHz(0-3:800MHz) mvm=0-3:100%
The PCIe interface is not enabled by default on PI5B. To enable it, add the following configuration in /boot/firmware/config.txt:dtparam=pciex1
2: PCIE is gen2 by default, if you need to enable PCIE gen3, add it in /boot/firmware/config.txt:
dtparam=pciex1_gen=3
Please enable PCIE gen3 as described in step 2.
At the moment, we have tested Raspberry Pi 5 official M.2 HAT and Seeed Studio Dual M.2 HAT, both working successfully. We know of more users succesfully testing other HATs.
The PCIe interface is not enabled by default on PI5B. To enable it, add the following configuration in /boot/firmware/config.txt:dtparam=pciex1
2: PCIE is gen2 by default, if you need to enable PCIE gen3, add it in /boot/firmware/config.txt:
dtparam=pciex1_gen=3
At the moment, we have tested Raspberry Pi 5 official M.2 HAT and Seeed Studio Dual M.2 HAT, both working successfully. We know of more users succesfully testing other HATs.
Thank you for the reply I will try it with the seed hat and update you
Is your RPi5 set to PCIe Gen3, @dev.manek?
dtparam=pciex1_gen=3
Is your RPi5 set to PCIe Gen3, @dev.manek?
dtparam=pciex1_gen=3
Yes I did. I can confirm that it works with seed dual m.2 hat. But still no stream. WARNING : Failed to get OpenCL platforms : clGetPlatformIDs failed: PLATFORM_NOT_FOUND_KHR EDIT:- I am dumb I had no display on. Everything works. Thank you so much guys.
Is your RPi5 set to PCIe Gen3, @dev.manek?
dtparam=pciex1_gen=3
Yes I did. I can confirm that it works with seed dual m.2 hat. But still no stream. WARNING : Failed to get OpenCL platforms : clGetPlatformIDs failed: PLATFORM_NOT_FOUND_KHR EDIT:- I am dumb I had no display on. Everything works. Thank you so much guys.
Ah nice work! It’s easy to overlook these things Just glad it’s up and running!
What’s the project you’re building with it @dev.manek?
(venv) root@iak:/voyager-sdk# AXELERA_OPENGL_BACKEND=gles,3,1 ./inference.py yolov8s-coco-onnx ./media/traffic1_480p.mp4 INFO : Using device metis-1:1:0 WARNING : Failed to get OpenCL platforms : clGetPlatformIDs failed: PLATFORM_NOT_FOUND_KHR WARNING : Please check the documentation for installation instructions INFO : Default OpenGL backend gl,3,3 overridden, using gles,3,1 INFO : Network type: NetworkType.SINGLE_MODEL INFO : Input INFO : └─detections Stream Paused: 57%|████████████████████████████████████████ | 4/7 �00:00<00:00, 106.96/s]�ERROR]�axeWaitForCommandList]: Uio wait kernel failed with return code -1600. �ERROR][axeCommandQueueExecuteCommandListsAsync]: Waiting for command lists failed: 0x70010001. terminate called after throwing an instance of 'std::runtime_error' what(): axr_run_model failed with Error at zeCommandQueueExecuteCommandLists(cmdqueue, n_cmdlists, cmdlists, nullptr): cmdqueue_run_cmdlists: 309: Exit with error code: 0x70010001 : ZE_RESULT_ERROR_NOT_AVAILABLE Aborted (core dumped)
So my guess is that I cannot access the OpenCL platform which is needed for inference.
However when I run the OpenCL demo with gears (the glxgears command from the guide), it runs just fine. also when I run clinfo command, it shows that I have 0 platforms: (venv) root@iak:/voyager-sdk# clinfo Number of platforms 0
Any ideas on the solution directions from here?
Best wishes,
Ivan
We’ll check this with @Victor Labian, but I don’t think OpenCL is support on the Pi5, in the Voyager SDK context. I think there’s been some experimentation around enabling it, but it’s not straight forward (or officially supported) yet - I could be wrong though.
During some quick research, I did see that --pipe=torch-aipu has been used to skip OpenCL entirely - might be worth a shot in the meantime? I’ve not tried this (?!) so forgive me if it wastes any time (I don’t have a spare Pi5 to test), but I’m guessing that’d be…
Presumably slower, but might work at least, in the meantime. Let me know how it goes, and we’ll get our Raspberry Ninja (that’s Victor ) to check in too
Hello @Spanner @IAK ,
OpenCL is not officially supported on Raspberry Pi 5. We are exploring possibilities of how to enable OpenCL in RPi 5 and then be able to work on Voyager SDK with it on RPi5 but that is something that we cannot disclosure more about at the moment.
However, OpenCL is not the issue, it is only a warning, as inference should also be able to run without OpenCL.
As I mentioned before to @dev.manek we have tested Raspberry Pi 5 official M.2 HAT and Seeed Studio Dual M.2 HAT, both working successfully. For other HATs you might need to read the documentation for the HAT and/or contact the manufacturer. I suggest that you test any of the two HATs we have confirmed that work well.
@IAK :
which HAT are you using?
Can you run inside the (venv) the command axdevice --refresh and share the output with us?
Can you also share the output of running the following:
uname -r
cat /sys/class/metis/version
lsmod | grep metis
Best,
Victor
Hiya,
I’m on the same team as @IAK. We’re running it on the official RPI M.2 HAT+. The result from the commands is:
When I run it with the pipe=torch-aipu (with -v as well), I get the following results:
The first time I ran it, I got this. It seems to me it managed some detections but then got stuck somewhere? Or that it was querying from None. It did get further than without the torch-aipu, as a little window with the Axelera logo opened up which hadn’t happened before.
(venv) root@iak:/voyager-sdk# ./inference.py yolov8s-coco-onnx ./media/traffic1_480p.mp4 --pipe=torch-aipu -v DEBUG :axelera.app.inf_tracers: HostTracer will write to /tmp/tmp36tq5ajq INFO :axelera.app.device_manager: Using device metis-1:1:0 DEBUG :axelera.app.network: Create network from /voyager-sdk/ax_models/zoo/yolo/object_detection/yolov8s-coco-onnx.yaml DEBUG :axelera.app.network: Register custom operator 'decodeyolo' with class DecodeYolo from /voyager-sdk/ax_models/decoders/yolo.py DEBUG :axelera.app.device_manager: Reconfiguring devices with ddr_size=1.0GB, device_firmware=1, mvm_utilisation_core_0=100%, clock_profile_core_0=800MHz DEBUG :axelera.app.inf_tracers: Host FPS multiplier: 1 WARNING :axelera.app.utils: Failed to get OpenCL platforms : clGetPlatformIDs failed: PLATFORM_NOT_FOUND_KHR WARNING :axelera.app.utils: Please check the documentation for installation instructions WARNING :axelera.app.utils: pyglet could not access the display, OpenGL is not available: Could not create GL context INFO :axelera.app.pipe.manager: Network type: NetworkType.SINGLE_MODEL INFO :axelera.app.pipe.manager: Input INFO :axelera.app.pipe.manager: └─detections DEBUG :yolo: Model Type: YoloFamily.YOLOv8 (YOLOv8 pattern: DEBUG :yolo: - 6 output tensors (anchor-free) DEBUG :yolo: - 3 regression branches (64 channels) DEBUG :yolo: - 3 classification branches (80 channels) DEBUG :yolo: - Channel pattern: e64, 64, 64, 80, 80, 80] DEBUG :yolo: - Shapes: : 1, 80, 80, 64], 01, 40, 40, 64], 01, 20, 20, 64], 01, 80, 80, 80], 01, 40, 40, 80], 01, 20, 20, 80]]) DEBUG :axelera.app.pipe.io: FPS of /root/.cache/axelera/media/traffic1_480p.mp4: 60 INFO :axelera.app.torch_utils: Using CPU based torch DEBUG :axelera.app.pipe.io: Create image generator from VideoCapture DEBUG :axelera.app.operators.inference: Loaded model : /voyager-sdk/build/yolov8s-coco-onnx/yolov8s-coco-onnx/1/model.json DEBUG :axelera.app.operators.inference: Available ONNX runtime providers: 'AzureExecutionProvider', 'CPUExecutionProvider'] WARNING :axelera.app.stream: Timeout for querying an inference DEBUG :axelera.app.operators.inference: Expected core model output shape: tp1, 64, 80, 80], 41, 64, 40, 40], 41, 64, 20, 20], 41, 80, 80, 80], 01, 80, 40, 40], 01, 80, 20, 20]] ERROR :axelera.app.display: Exception in inference thread: InferenceThread ERROR :axelera.app.display: Traceback (most recent call last): ERROR :axelera.app.display: File "/voyager-sdk/axelera/app/display.py", line 270, in _target ERROR :axelera.app.display: target(*args, **kwargs) ERROR :axelera.app.display: File "/voyager-sdk/./inference.py", line 48, in inference_loop ERROR :axelera.app.display: for frame_result in tqdm( ERROR :axelera.app.display: File "/root/.cache/axelera/venvs/fd8d4664/lib/python3.10/site-packages/tqdm/std.py", line 1181, in __iter__ ERROR :axelera.app.display: for obj in iterable: ERROR :axelera.app.display: File "/voyager-sdk/axelera/app/stream.py", line 175, in __iter__ ERROR :axelera.app.display: raise RuntimeError('timeout for querying an inference') from None ERROR :axelera.app.display: RuntimeError: timeout for querying an inference DEBUG :axelera.app.meta.object_detection: Total number of detections: 6
The second time I ran it I got the following:
(venv) root@iak:/voyager-sdk# ./inference.py yolov8s-coco-onnx ./media/traffic1_480p.mp4 --pipe=torch-aipu -v DEBUG :axelera.app.inf_tracers: HostTracer will write to /tmp/tmpp_o2jqie INFO :axelera.app.device_manager: Using device metis-1:1:0 DEBUG :axelera.app.network: Create network from /voyager-sdk/ax_models/zoo/yolo/object_detection/yolov8s-coco-onnx.yaml DEBUG :axelera.app.network: Register custom operator 'decodeyolo' with class DecodeYolo from /voyager-sdk/ax_models/decoders/yolo.py DEBUG :axelera.app.device_manager: Reconfiguring devices with ddr_size=1.0GB, device_firmware=1, mvm_utilisation_core_0=100%, clock_profile_core_0=800MHz DEBUG :axelera.app.inf_tracers: Host FPS multiplier: 1 WARNING :axelera.app.utils: Failed to get OpenCL platforms : clGetPlatformIDs failed: PLATFORM_NOT_FOUND_KHR WARNING :axelera.app.utils: Please check the documentation for installation instructions WARNING :axelera.app.utils: pyglet could not access the display, OpenGL is not available: Could not create GL context INFO :axelera.app.pipe.manager: Network type: NetworkType.SINGLE_MODEL INFO :axelera.app.pipe.manager: Input INFO :axelera.app.pipe.manager: └─detections DEBUG :yolo: Model Type: YoloFamily.YOLOv8 (YOLOv8 pattern: DEBUG :yolo: - 6 output tensors (anchor-free) DEBUG :yolo: - 3 regression branches (64 channels) DEBUG :yolo: - 3 classification branches (80 channels) DEBUG :yolo: - Channel pattern: h64, 64, 64, 80, 80, 80] DEBUG :yolo: - Shapes: yo1, 80, 80, 64], 11, 40, 40, 64], 11, 20, 20, 64], 11, 80, 80, 80], 11, 40, 40, 80], 11, 20, 20, 80]]) DEBUG :axelera.app.pipe.io: FPS of /root/.cache/axelera/media/traffic1_480p.mp4: 60 INFO :axelera.app.torch_utils: Using CPU based torch DEBUG :axelera.app.pipe.io: Create image generator from VideoCapture DEBUG :axelera.app.operators.inference: Loaded model : /voyager-sdk/build/yolov8s-coco-onnx/yolov8s-coco-onnx/1/model.json DEBUG :axelera.app.operators.inference: Available ONNX runtime providers: t'AzureExecutionProvider', 'CPUExecutionProvider'] Detecting... : 0%| | 0/13363 00:02<?, ?frames/s]lERROR]faxeLoadAndExecuteQueueElf]: Uio wait kernel failed with return code -1406. oERROR]0axeRunQueueCSourceCommandLists]: Load and execute queue elf failed: 0x70010001. xERROR]0axeCommandQueueExecuteCommandListsSync]: Run command lists failed: 0x70010001. ERROR :axelera.runtime: Error at zeCommandQueueExecuteCommandLists(cmdqueue, n_cmdlists, cmdlists, nullptr): cmdqueue_run_cmdlists: 309: Exit with error code: 0x70010001 : ZE_RESULT_ERROR_NOT_AVAILABLE ERROR :axelera.app.pipe.torch: TorchPipe terminated due to RuntimeError at /root/.cache/axelera/venvs/fd8d4664/lib/python3.10/site-packages/axelera/runtime/objects.py:74: AXR_ERROR_RUNTIME_ERROR: Error at zeCommandQueueExecuteCommandLists(cmdqueue, n_cmdlists, cmdlists, nullptr): cmdqueue_run_cmdlists: 309: Exit with error code: 0x70010001 : ZE_RESULT_ERROR_NOT_AVAILABLE ERROR :axelera.app.pipe.torch: Full traceback: ERROR :axelera.app.pipe.torch: File "/voyager-sdk/axelera/app/pipe/torch.py", line 55, in _loop ERROR :axelera.app.pipe.torch: image, result, meta = model_pipe.inference.exec_torch( ERROR :axelera.app.pipe.torch: File "/voyager-sdk/axelera/app/operators/inference.py", line 750, in exec_torch ERROR :axelera.app.pipe.torch: self._axr_modeli.run(inputs, outputs) ERROR :axelera.app.pipe.torch: File "/root/.cache/axelera/venvs/fd8d4664/lib/python3.10/site-packages/axelera/runtime/objects.py", line 510, in run ERROR :axelera.app.pipe.torch: _raise_error(self.context, res.value) ERROR :axelera.app.pipe.torch: File "/root/.cache/axelera/venvs/fd8d4664/lib/python3.10/site-packages/axelera/runtime/objects.py", line 74, in _raise_error ERROR :axelera.app.pipe.torch: raise exc(f"{err}: {msg}") INFO : Core Temp : 39.0°C INFO : prep : 37.9us INFO : Memcpy-in : 562.5us INFO : Kernel : 34663.2us INFO : Memcpy-out : 459.3us INFO : Host : 28.0fps INFO : CPU % : 15.5% INFO : End-to-end : 0.0fps
When running it with --pipe=torch it does work, but seems to be running on CPU with ~1 FPS.
Thanks for running those check @GeertL! This is good stuff.
So it looks like all system-level and SDK checks pass. The board is visible, the firmware and driver are correctly installed, and the Pi environment looks to be configured appropriately. The inference error may then be related to runtime resource issues, subtle PCIe instability, or pipeline issues?
Let’s ask @Victor Labian if he has any thoughts on the most practical next step!
Also, if you do inference.py --help you can see what each command line options means. In this case:
--pipe {gst,torch,torch-aipu,quantized}
specify pipeline type:
- gst: C++ pipeline based on GStreamer (uses AIPU)
- torch-aipu: PyTorch pre/post-processing with model on AIPU
- torch: PyTorch pipeline in FP32 for accuracy baseline (uses ONNXRuntime for ONNX models)
The fact that you see low FPS is expected as:
With torch-aipu you are running non-optimized PyTorch pre/post-processing, that is really demanding on the host, and the RPi5 doesn’t have a very powerful CPU.
With torch you are running the whole pipeline in the CPU which is extremely slow.
You should use gst, which is the default and using optimised pre/post processing and Metis for inference.
Note that even Metis is very fast, the Raspberry Pi 5 will be the bottleneck as it does the pre/post processing.
FYI @Spanner
Best,
Victor
Hi everyone!
Some update from my side:
We’ve decided to try deploying the model on another machine - a PC with Ubuntu 20.04 on it. We then installed the Docker container there and @GeertL was able to run the inference.py script on it. Big Win.
As for Raspberry Pi 5 host, we still face same issues as before. Answering the question above, we have enabled the PCIE gen. 3 in the raspi-config. Any ideas on where to move from here?
I have noticed a weird bug while working on Ubuntu 20.04 machine. After rebooting the machine, the accelerator is not recognized, and lspci doesn’t list it. I’ve tried changing the GRUB config as was mentioned in this post
However, it didn’t help. However if the system is completely powered off, and turned on afterwards, the chip is recognized and after running sudo update-pciids, it has the proper naming. Is there solution for this issue?
Best,
Ivan
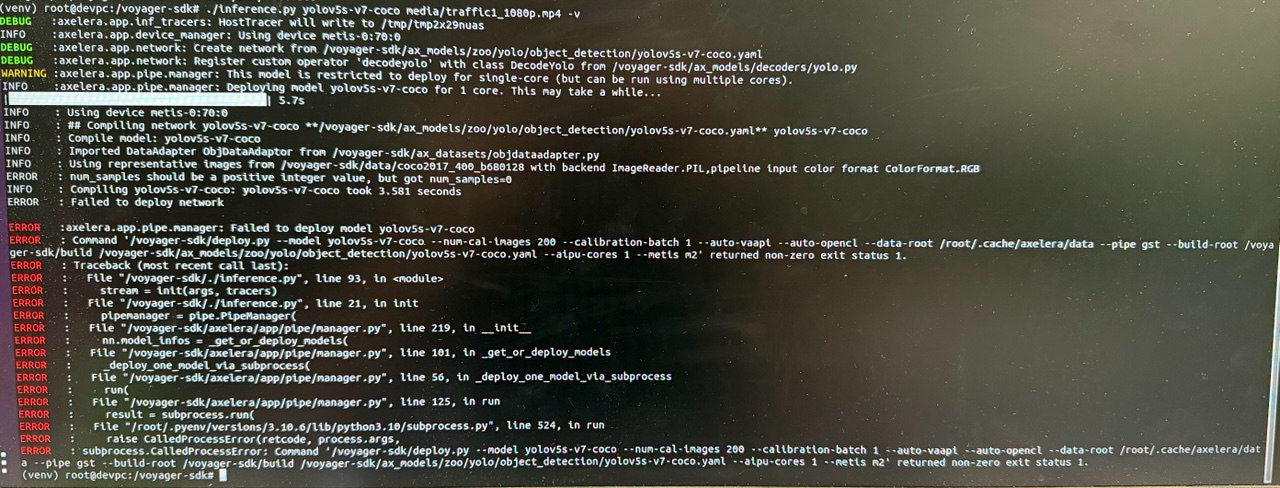
OK one more update:
the inference on out PC host doesn’t work now too. the error is that it fails to deploy it. Here’s the verbosed command output: (Sorry for the image posting move, can’t access this page from my host PC)
Any ideas for the solution?
Best,
Ivan
I wonder if the dataset hasn’t been downloaded? Perhaps if you could take a look at this, and let me know if that helped? Then we can pick up from there if not



 Thanks for the info.
Thanks for the info. ) to check in too
) to check in too