Douglas Watt | Director of AI Application Engineering at AXELERA AI
![]()

Ioannis Koltsidas | VP AI Software at AXELERA AI
![]()
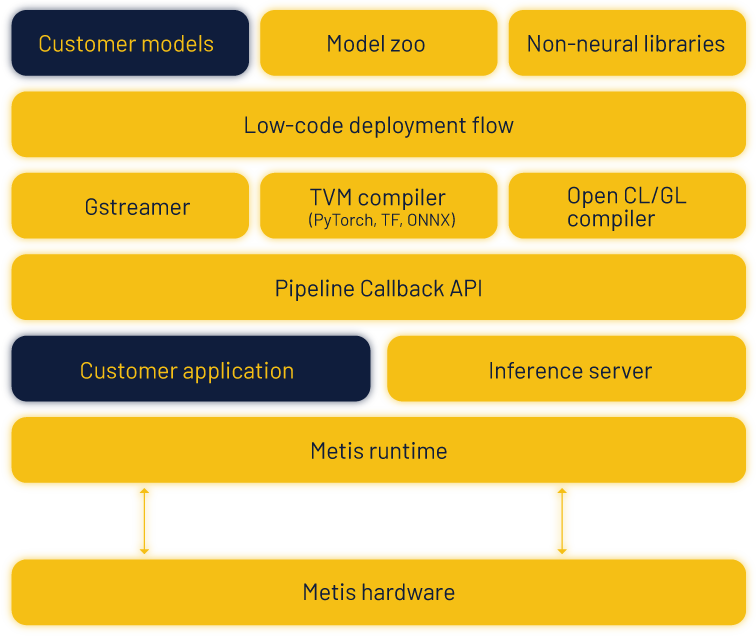
Machine learning frameworks such as PyTorch and TensorFlow are the de facto tools that AI developers use to train models and develop AI applications because of the powerful capabilities they provide. In this article, we introduce the Voyager SDK, which developers can use to deploy such applications to the Metis AI PU quickly, effortlessly and with high performance.
What is different at the Edge?
Machine learning frameworks are designed around the use of 32-bit floating point data, which has the precision needed to train models using standard backpropagation techniques. Models are often trained in the data center using powerful but expensive, energy-inefficient GPUs, and in the past these models were often used directly for inferencing on the same hardware. However, this class of hardware is no longer needed to achieve high inference accuracy and today’s challenge is how to efficiently deploy these models to lower cost, power-constrained devices operating at the network edge.
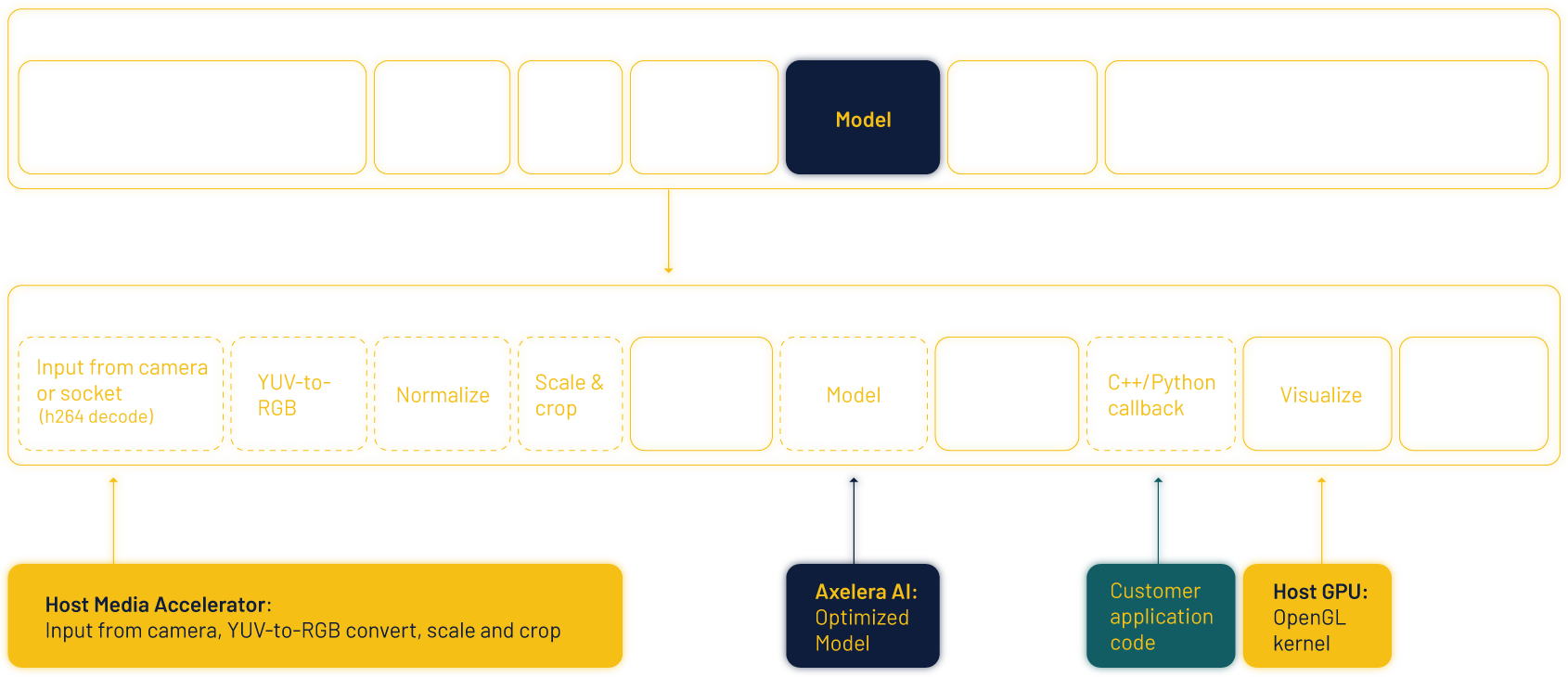
A complete AI application involves a pipeline of multiple tasks. For example, a computer vision application typically combines a deep learning model that operates on tensor data with various pre and post processing tasks that operate on non-tensor data such as pixels, labels and key points. The latter, also referred to as non-neural tasks, prepare data for input to the deep learning model. Examples include scaling an image to the model’s input resolution and encoding the image to the required tensor format. Non-neural tasks are also used to interpret the predicted output tensors, for example generating an array of bounding boxes.
For ease of development, most models are implemented and trained in high-level languages such as Python. However, most inference devices rely on low-level embedded programming to achieve the requisite performance. The core deep learning model is usually defined within the tight constraints of the ML framework, which enables the use of quantization tools to optimize and compile the model to run as native assembly on the target AI accelerator. The non-neural tasks are often more general-purpose in their design and their optimal location may vary from one platform to the next. In the example above, preprocessing elements are offloaded to an embedded media accelerator, and visualization elements reimplemented as OpenGL kernels on an embedded GPU. Furthermore, combining these heterogeneous components efficiently requires the use of a low-level language such as C++ and libraries that enable efficient buffer sharing and synchronization between devices. Many application developers are not familiar with low-level system design and thus providing developers with easy-to-use pipeline deployment tools is a prerequisite to enable the mass adoption of new Edge AI hardware accelerators in the market.
Simplifying AI development for the Edge
The Voyager SDK offers a fast and easy way for developers to build powerful and high-performance applications for Axelera AI’s Metis AI platform. Developers describe their end-to-end pipelines declaratively, in a simple YAML configuration file, which can include one or more deep learning models along with multiple non-neural pre and post processing elements. The SDK toolchain automatically compiles and deploys the models in the pipeline for the Metis AI platform and allocates pre and post processing components to available computing elements on the host such as the CPU, embedded GPU or media accelerator. The compiled pipeline can then be used directly as a first-class object from Python or C++ application code as an “inference input/output stream”.