
Huge updates today for ABC Project.
We are starting the development of the first part of object recognition based on Metis of the entire process pipeline, in order to make the OCR simpler and more accurate (i.e. less capable of delivering wrong results).
All these operations are both to be done in real world and on software, as we need to start with a proper and repeatable hardware setup prior to properly set software up.
The first operation in the real world is to bound a specific area with masking tape, which we call the loading area, where the book to be processed will be placed; this area is just below the camera.
After this, we draw an X on each corner of the loading area's rectangle, with a black marker on the masking tape and a calibration procedure based on OpenCV library detects the rectangle to crop later the acquired images.

The next action, in order to make the setup repeatable, is to measure the height of the camera from the tabletop where the loading area is located; this height for the SONOF CAM-S2 is 40cm (15" 3/4), so we added a ring light with adjustable arm to support the camera exactly over the load area.
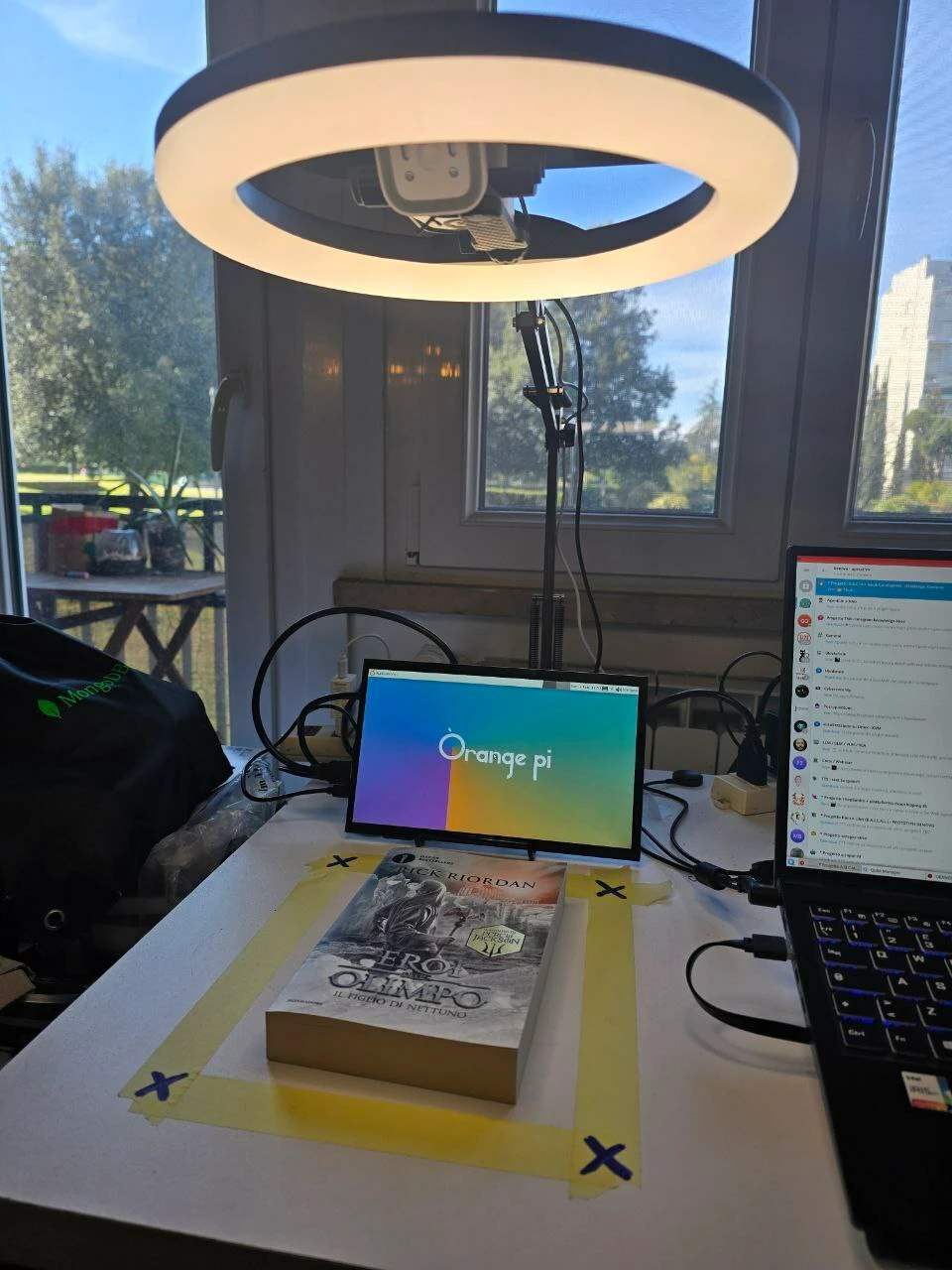
The third step in the hardware setup is leveling the camera to ensure it is parallel to the tabletop, preventing image distortion and blur. So we added on the back of the camera a double bubble level.

Now we can start with software; the loading area is interpreted by OpenCV as a cropping of the entire picture provided by camera; this crop is passed to OCR which has to examine only the part where we put the book in real world.
At this point we have tried different OCR models, but to have a reliable process it is clear we should have some comparing source. We have done some tests adding an LLM model (like llama), but it was too creative and we cannot be sure it really helps the OCR acquisition.
So we switched to an old-school solution, based on real books data. Luckily the Open Library project let us download (and freely use!) a 12GB dump of a lot of italian and international books, authors and publishers. Then we have integrated these information in a local db that we can use offline.
At the moment we are integrating this new source of data with the OCR pipeline to match better the data acquired.
We will update soon on next step!
In the while we have started to publish all the code on github and we keep the kanban updated :)

