

This week, I focused on the AI aspects of the Summer SideKick project. I explored the model zoo to identify models already tested and validated on the platform, and I also ran experiments with the Voyager SDK to get comfortable with tasks such as model deployment, application development workflows, and more.
For the data processing pipelines, I decided to start with a mid-size model for the first stage, which will handle the main classification task. For the next stages, which are more related to the application itself, I haven’t finished the exploration of algorithms and models yet. The SDK already provides an off-the-shelf tracker model, which I plan to use for monitoring pet activity. For other tasks, I’m considering fine-tuning CNN-based models such as MobileNet or a YOLO variation. The use of OpenCV also remains an option.
Here is the pipeline I plan to implement next week:
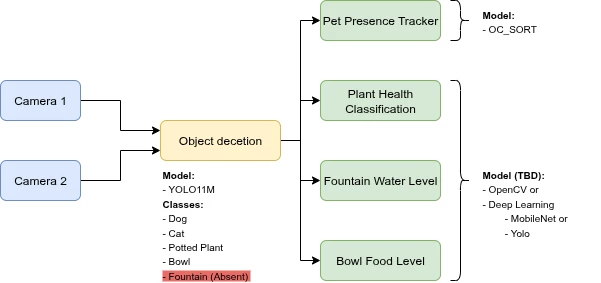
Next week, I’ll move forward with implementing these models in the pipeline and testing how they perform on real data from the hardware setup. I’d really appreciate your feedback on whether this seems like a solid approach, and any suggestions for improving the computer vision pipeline.