

This piece covers the how. If you want the why, our companion article makes the business case for edge AI in physical security.
At a Glance
-
The Achievement: Real-time AI person-of-interest (POI) identification and threat detection across multiple 8K streams at 2.5 PetaOPS
-
The Stack: Voyager SDK + Axelera Metis + Intel Xeon
-
The Future: 3x performance leap with the next-gen Europa architecture
Nothing matches the energy of ISC West for showcasing what we’ve been building. As we move between major industry events, we’re constantly hearing from enterprise leaders that the 'pilot phase' of Edge AI is truly over. The challenge now is scale. It’s no longer about running a single model on a single stream. It’s about the massive task of orchestrating dozens of AI models across multiple video feeds at commercially viable costs.
Returning to this show in 2026 with our most ambitious interactive experience yet, is a turning point. It provides the perfect backdrop to demonstrate exactly how we’re pushing the limits of real-time, multi-model, and high-resolution multi-stream security.
Last year we demonstrated a pioneering approach to 8k AI inferencing. Today, we’re expanding the Voyager SDK with safety-focused capabilities, including person-of-interest identification and an alerting and visualisation framework. These tools are designed to improve operator response times, particularly when potential weapons are detected on the show floor. In collaboration with four ISV partners, we’ve developed a security demonstration showing how easily customers can train, deploy, and integrate custom models into our end-to-end software pipelines to deliver plug-and-play AI solutions at scale. This showcase highlights the maturity of the Voyager SDK.
If you are ready to build something like this yourself, here is where it gets interesting.
Production Pipelines for Scalable Real-World Systems
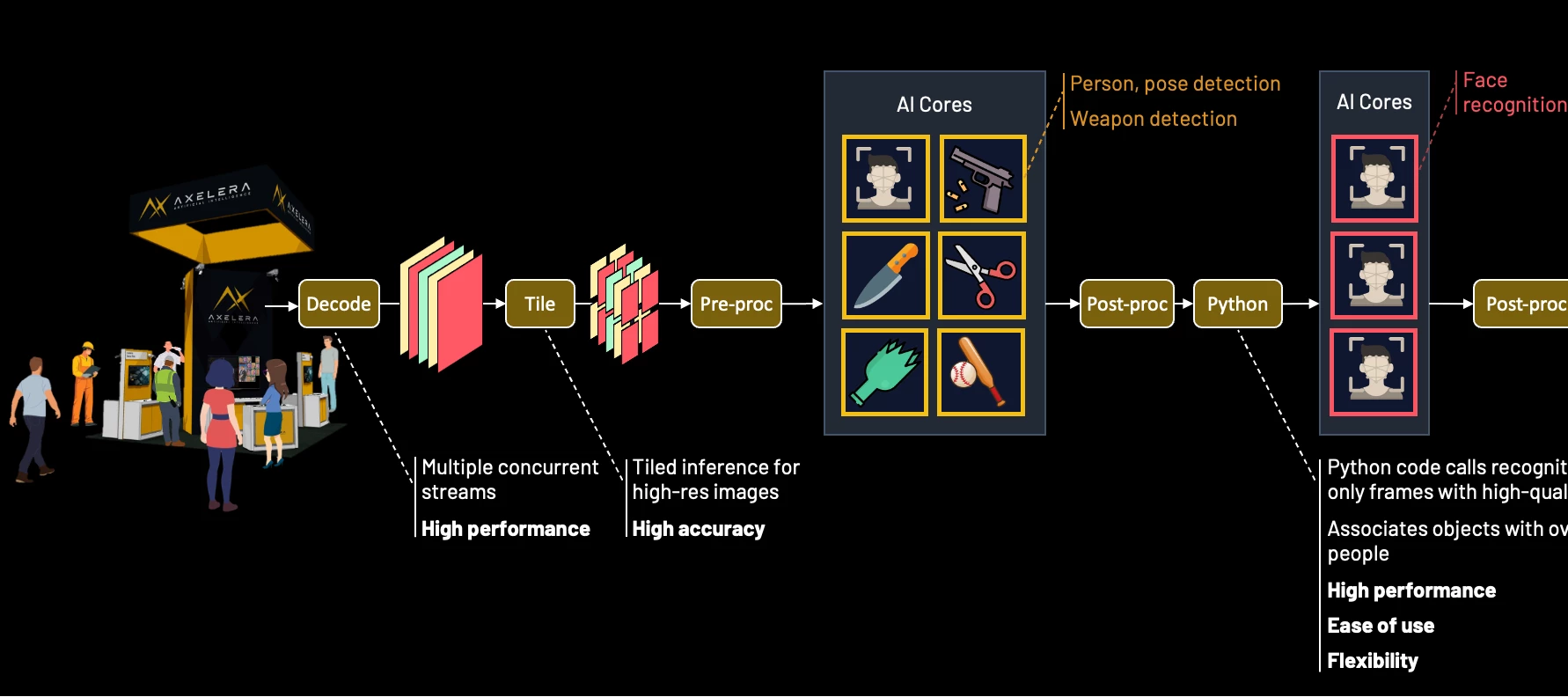
When you build on Axelera's Metis AIPUs and the Voyager SDK, you gain a complete set of capabilities for orchestrating high-concurrency, multi-stream AI workloads out of the box. Here is what developers can tap into:
-
Hardware-accelerated decoding: Ingest and decode multiple 4K and 8K video streams simultaneously to maintain low latency and high throughput
-
Tiling-based pre-processing: Subdivide high-resolution streams into overlapping tiles to ensure the AI detects small objects with high precision, while applying perspective transformations to normalize different camera angles
-
Concurrent analytics: Run multiple models in parallel to detect and track individuals, face landmarks, and objects of interest simultaneously
-
Model cascading: Pass detector outputs to secondary models; for example, output regions of interest from a face detector to a recognition model
-
Custom pipeline logic: Integrate user-defined code; for example, implement conditional logic to select specific frames or regions of interest to pass to secondary models
-
Intelligent edge orchestration: Optimise bandwidth by sending only critical metadata/events to the cloud while retaining raw high-resolution footage for local forensic storage
New to the Voyager SDK
Support for custom C++ and Python logic within the pipeline, providing the architectural flexibility demanded by modern, high-performance applications.
Real-Time Person-of-Interest Identification
The Challenge
Real-world environments are far from ideal for identifying and tracking people of interest. The subject moves through crowds and around objects that obscure the view of them and they may actively avoid cameras, looking away or moving through dense crowds. Systems must also contend with challenging conditions such as poor lighting, motion blur, and varied facial angles.
Facial recognition models are highly sensitive to the quality of input. Indiscriminately processing blurry, angled, or partially occluded faces increases false rejections (failing to identify a known subject) and false identifications (incorrect matches), all while wasting valuable AI processing cycles.
The Solution
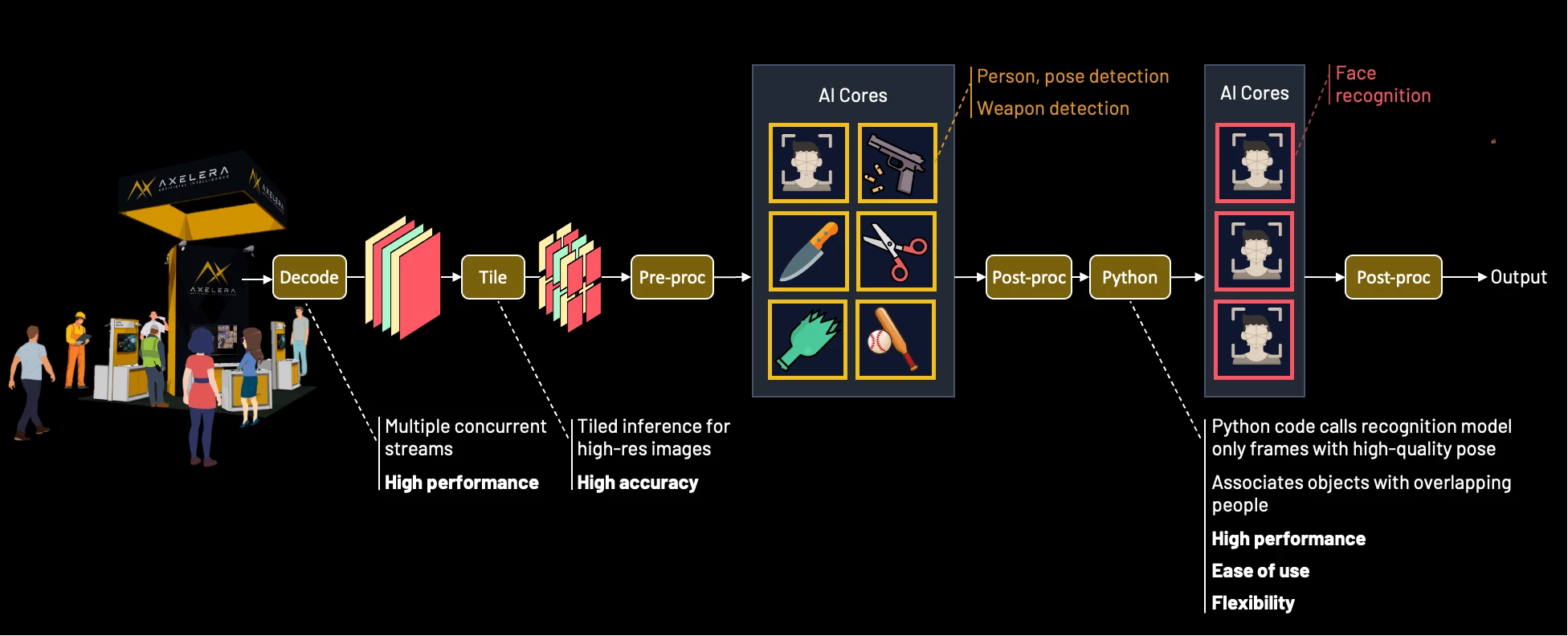
A shift is necessary from frame-by-frame recognition to more nuanced temporal processing. By inserting a tracker after the detector, developers can identify the same individual across multiple frames and construct a pose-quality buffer for each tracker ID. Combined with conditional logic, this allows the system to filter for only the highest-quality detector crops, preserving processing power while improving accuracy.
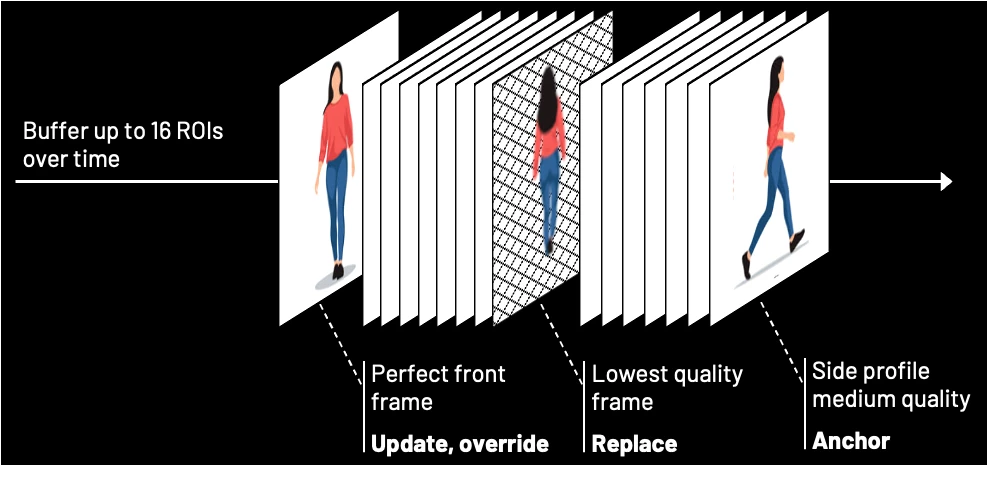
As a tracked person moves through a scene, their associated pose-quality buffer is populated with the best available regions of interest based on metrics such as pose angle, pixel density, and illumination. Each new region of interest replaces the weakest frame in the buffer only if its score is higher. Over time, poor angles and blurs are filtered out, ensuring only the most reliable data reaches the recognition model.
Anchor and Update
The first high-quality region of interest detected can be immediately cascaded to the recognition model, allowing the system to make a primary identification while the pose-quality buffer populates. Once the buffer reaches a defined threshold, the system performs batch processing to refine the result. Instead of treating each match in isolation, the recognition outputs are combined using a Bayesian update to produce a cumulative confidence score. This effectively amplifies multiple lower-confidence matches into a single, high-certainty identification.
This process treats each new region of interest as a multiplier of existing evidence. Mathematically, two independent 70% matches provide greater certainty than a single 90% match. This architecture ensures temporal stability and resilience against noise or outliers. Once a high-confidence identity is established through multiple high-quality frames, transient data from a blurry frame or passing occlusion will not overturn the cumulative evidence.
Secure the Critical Moment
An override gate ensures that the system identifies subjects who may only appear clearly for a single frame. If an incoming region of interest achieves a high-quality frontal pose and returns a high-confidence match, the identification is considered immediately reliable. This triggers an instant alert and can be configured to supersede the existing buffer of lower-quality data. This mechanism prevents temporal blindness by ensuring that even a fleeting, high-quality glimpse of a subject results in a successful identification.
The Axelera Surveillance Blueprint
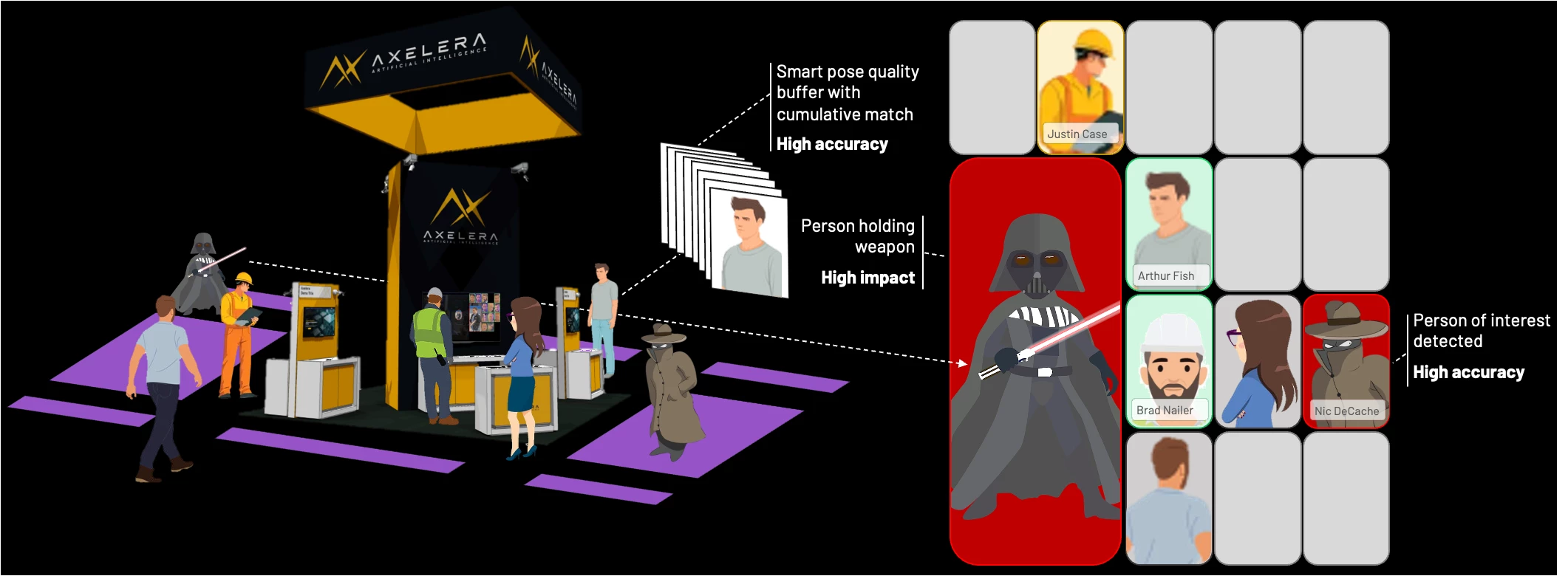
Next, we put the person-of-interest tracker together with real-time weapon detection, designed specifically for multi-model concurrency. This blueprint allows developers to easily extend the system by running a range of analytics models in parallel.
To maximise detection reliability, each subject is represented as a detection pair: person and face. By running person and face detection models in parallel on every frame, the system maintains dual-path tracking: faces can be identified even when bodies are occluded by crowds or objects, while individuals can be tracked when their face is not visible. The application dynamically maps overlapping detections to maintain a persistent identity for each subject.
The pipeline is configured to prevent frame-drop: if a new frame arrives before all recognition tasks complete, the remaining tasks are asynchronously scheduled across subsequent detections. This allows the system to iteratively scan and resolve an entire scene over time without compromising camera throughput (similar to how a human would process the scene, just much faster).
The blueprint is engineered to commit fast and refine slow. It uses the first high-quality match to establish an initial identity with low latency, while maintaining a pose-quality buffer to improve certainty over time. Combined with the override gate, this ensures that even brief, high-quality captures result in a successful identification.
To manage these detections, the interface displays all tracked individuals in a grid of high-resolution regions of interest, a crowd view. Utilising the full 33-million-pixel resolution, this enables operators to maintain visibility on distant subjects that would otherwise be lost to downscaling on most monitors. The interface uses bi-directional linking: when you hover over a person in the grid, the system draws a line to their position in the raw feed, and vice versa. At a single toggle, the grid can be configured to show the live view of each person or the best shot from the pose quality buffer.
Weapon Detection
While I’d have loved to show a realistic weapon demo, the venue (and the common sense of my colleagues) suggested that bringing firearms onto the show floor was a bad idea. Instead, I opted for a weapon from a more civilised age: a lightsaber.
For the weapon detection, I chose the unique curved hilt of Count Dooku, which serves as an ideal target for our demonstration. While a prop, its distinctive geometry is highly representative of tactical batons, bladed weapons, or firearm suppressors. This allows us to demonstrate high-precision detection with 8K native inferencing across a live, multi-camera environment in a way that’s high impact, but zero risk.

The Axelera surveillance blueprint configuration (as demonstrated at ISC West 2026):
-
Person-of-Interest Watchlist: Axelera staff are enrolled as the primary subjects for the person-of-interest identification tracking
-
Weapon Detection: The custom Ultralytics YOLOv8l lightsaber model acts as the weapon detector
-
8K Camera Setup: Two Axis Q1809-LE 8K IP cameras are positioned at the top of the booth to survey the show floor
-
8K Display: A 75” 8K monitor displays the two primary feeds (downsampled) on the left and the crowd view grid on the right
-
Focus View Cell: A large area within the grid highlights high-priority weapon alerts. When no alert is active, this space displays a live 4K feed from an internal booth camera for visitor interaction
-
Personal Protective Equipment (PPE) Verification: When the 4K booth camera detects a person in full PPE clothing, the interface illuminates with a green shield to signal compliance
-
Edge-to-Cloud Orchestration: Detections trigger an on-booth alarm while simultaneously pushing automated incident tickets to ServiceNow for remote response
The demo’s intelligence is a collaborative effort: Digica provided the face detection and recognition models, while Innowise developed the lightsaber detection model using a blend of Synthera’s synthetic data and real-world imagery. Additionally, SpanIdea contributed a PPE detection model that distinguishes between show attendees and construction workers.
Demo Hardware and Performance
To perform real-time inference of multiple models across parallel 8K streams, we utilised an ORIGIN L-Class V2 PC equipped with an Intel Xeon W7-3565X 32-core processor and a discrete GPU for the visual pipeline (decoding and 8K rendering).
The compute backbone consists of three Axelera 4-chip Metis cards, providing a total of 48 AIPU cores. This configuration delivers peak 2.5 PetaOPS of parallel processing power to handle the high-resolution tiling and model processing required.
The system is integrated into the booth infrastructure using a Ubiquiti Switch Pro XG 24 PoE, which provides high-bandwidth data transfer and power to the AXIS 8K cameras.
Running the surveillance blueprint at 8K resolution requires significant throughput to maintain real-time responsiveness. The system's performance is defined by the following metrics:
-
Tiling Throughput: The system processes 288 tiles/sec for the fully-configured blueprint.
-
Model Concurrency: Each 4-chip Metis card executes up to 16 model instances in parallel.
-
Total System Capacity: Across three cards, the system runs five primary models and one secondary model across 48 cores. This achieves a combined throughput of at least 1,440 model inferences/sec. This architecture ensures stable inference across all video feeds without thermal throttling or performance degradation.
-
Power Efficiency: Despite this high processing rate, the Metis architecture maintains a highly efficient power profile, with a typical draw of only 30–58W per card.
Looking Ahead: The Next Phase of Edge AI
For Axelera, innovation is constant. Our next-generation Europa architecture delivers a 3x performance increase over Metis, integrating on-chip video decoding and vector engines to accelerate preprocessing. This provides the critical AI headroom required by next-generation surveillance systems. Furthermore, the integration of custom Python logic into the Voyager pipeline marks the first step toward our Python-friendly Pipeline Builder API. This grants developers complete freedom to build complex, thread-safe pipelines with high-performance execution, directly delivering on our mission to make AI accessible to everyone.
Our growing ecosystem provides customers with an increasing choice of models and capabilities to integrate into their solutions. Axelera blueprints allow developers to 'mix and match' our model zoo with independent software vendor models. This enables autonomous edge-response that moves beyond simple alerting to initiating local, real-time defensive protocols, all while significantly reducing software costs and time-to-market.
Axelera uniquely delivers on all three critical requirements:
-
Ease of Use: Rapidly parameterise and customise for a wide range of embedded, desktop, and enterprise-grade hardware.
-
Flexibility: Manage diverse tasks and complex dataflow requirements within a single, modular pipeline.
-
Performance: Voyager SDK handles the low-level heavy lifting, such as multi-stream threading, buffer sharing and synchronisation, across cameras, decoders, the host CPU and Metis hardware.
By providing these foundational hardware and software blocks, Axelera AI enables high-performance security at scale, ensuring our customers stay ahead of evolving threats with ease.